Interactive document chatbot
Text embeddings and vectorization for interactive document retrieval and question-answering tasks, powered by GPTTypeScript
Next.js
React
Tailwind
MongoDB
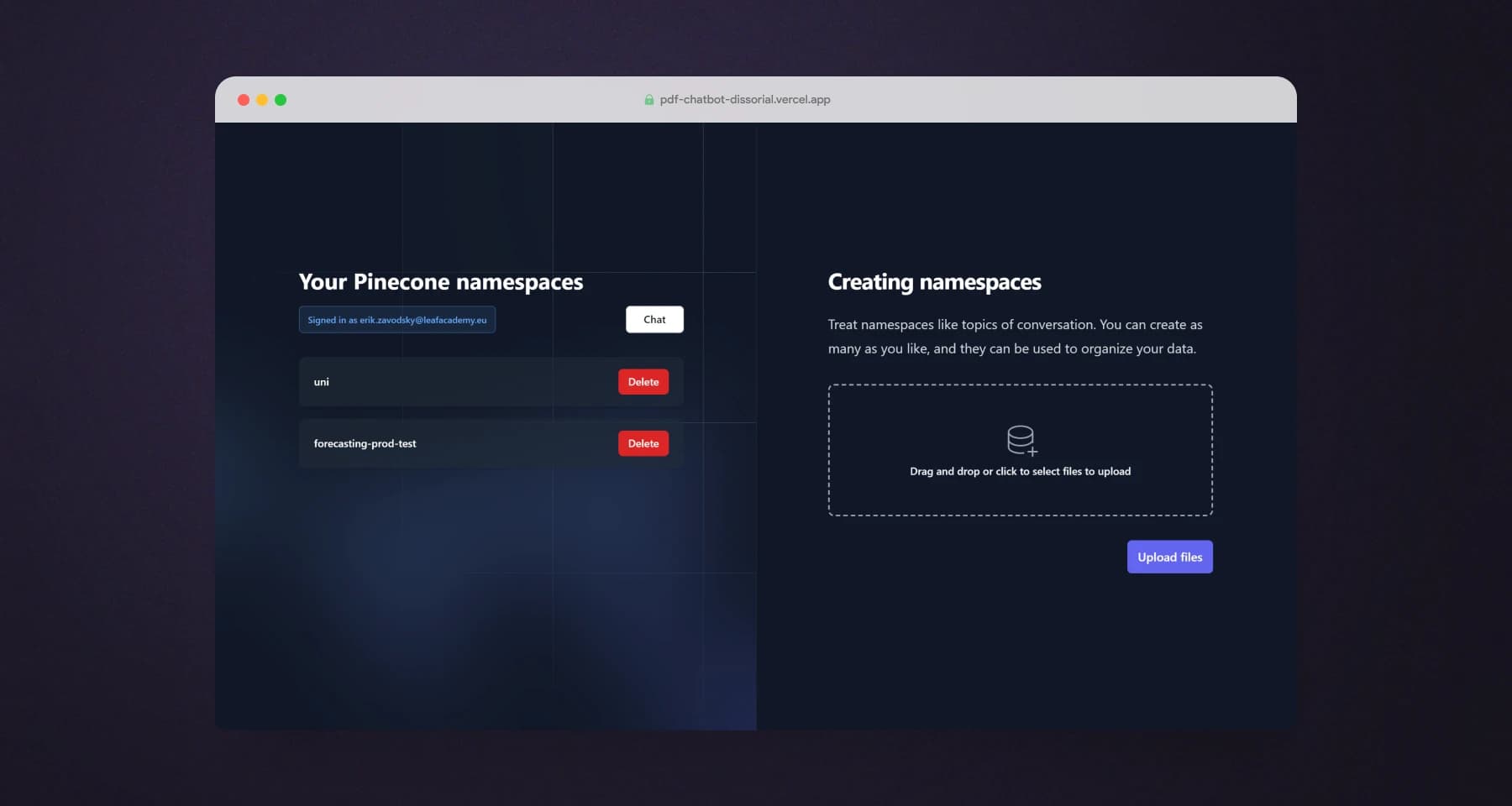
Pinecone
LangChain
Overview
Challenges & solutions
Challenge
Accurately parsing and extracting content from uploaded files involved various file formats with unique parsing intricacies. Handling temporary file uploads and precise deletion post-conversion in Vercel deployment was crucial.
Solution
I created API routes for uploading files to a temporary directory and extracting document content using open-source or LangChain document loaders. File content was converted to vector embeddings, stored in Pinecone and MongoDB namespaces, and temporary files were deleted.
Scroll
GithubGitHub link